

In this article, we’ll go through the details and meaning of REST. It will help you to better understand REST and use it with its best practices.
What is an API?
When developing software, we write API (Application Programming Interface) in order not to perform some tasks over and over again. The API insulates us from the difficulties of the environment and domain area where we work and ensures the encapsulation of complex processes and our abstraction from the domain area. Due to this, we stay away from low-level design architectural solutions and communicate with the environment only through the provided interface. For example, when using the framework, we can see all the DLLs (packages) whose functionality we benefit from as APIs.
What exactly is a web-based API?
Web Based API is just a variation of API. Web Based API is a form of API used to enable data exchange between applications using web standards and protocols. Typically, these types of APIs manifest themselves as REST APIs and SOAP services. Due to this, by creating a channel between different web resources (site, service, etc.), it is possible to build a large infrastructure (microservice, etc.) or simply an exchange mechanism.
The main topic of today’s article will be RESTful Services, one of the forms of Web Based API.
What exactly REST is?
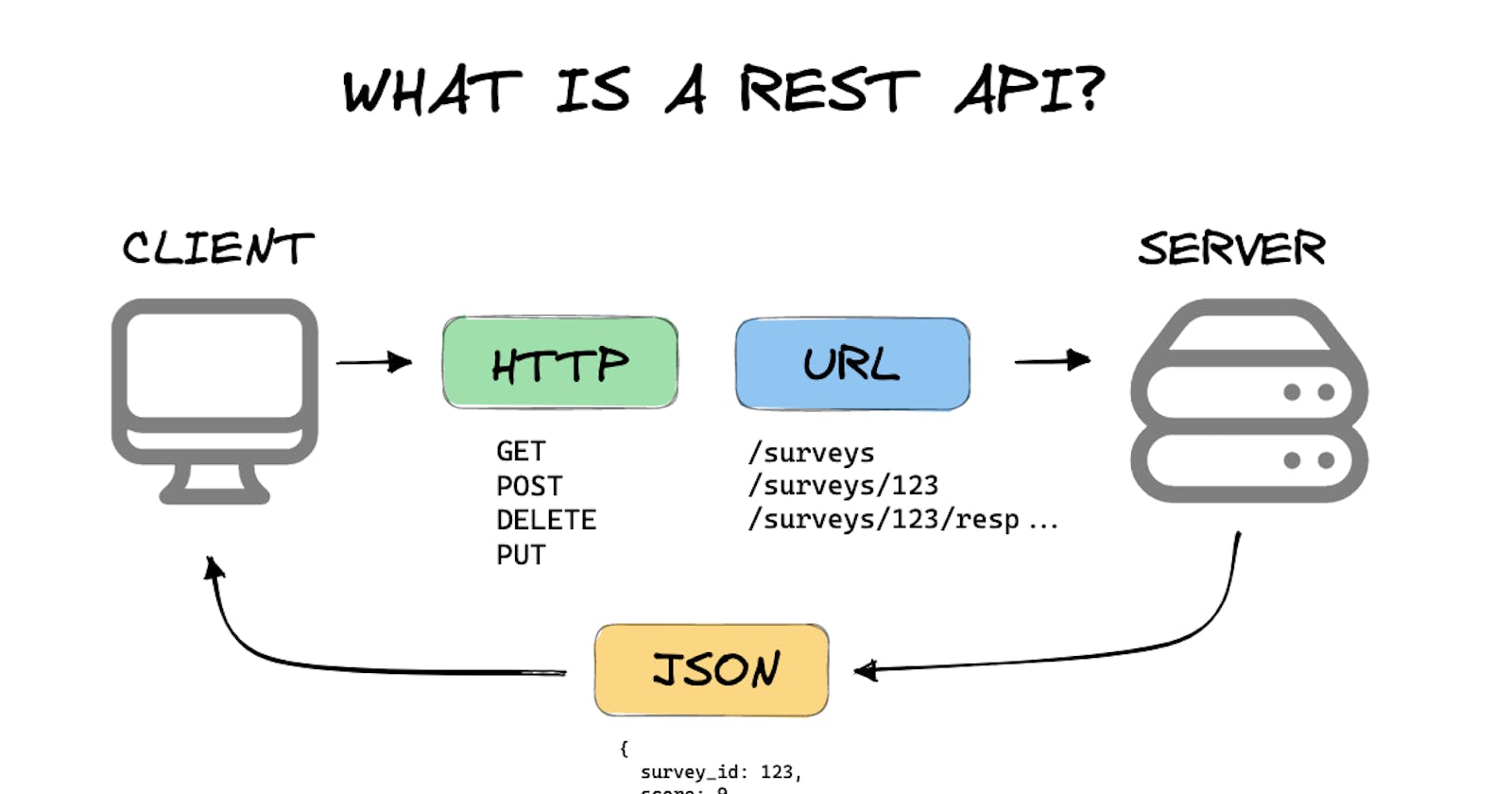
REST (Representational State Transfer) is an architectural style used to develop loosely-coupled applications over the HTTP protocol. REST is just an architectural style. The architectural style is: although the high-level architectural design of any work is given, the low-level design is kept free for the implementing party (vendor, provider).
REST is not a standard. Although REST is not a standard, it is implemented through web standards in modern days.
REST is not a protocol. Although REST is not a protocol, it has been implemented through web protocols (HTTP) nowadays. But REST is protocol-independent. The fact that it is implemented with the HTTP protocol doesn’t mean that it can only work with this protocol.
You can think of REST as a kind of ISO/OSI model. Although it is an ideal model, in real practice the TCP/IP model is used, and ISO/OSI remains a kind of theory. Although REST does not remain in theory, it is not excluded that it may be implemented in another format in the future.
If we express the work of REST in a short, we can say that “The client sends a request to the server, and the server changes the state of the client according to the response”.
As for the core of the word REST. REST is based on the concepts of Resource, Representation, State, and Transfer. First, the client requests a resource from the server. The server keeps the original resource in itself and sends the Representation, which is just a copy of it, to the client. If the resource changes tomorrow, the client must request again and get the latest state of the resource again. The transfer of the resource from the server to the client is just a Transfer.
Why do we need REST
It isolates the Client and Server from each other and eliminates the dependency between them.
It does not depend on any platform
It does not depend on any programming language. Whether you use PHP, C#, Node.js, etc. you can write REST services with all of them.
It is not tied to a specific format. You can receive data in either XML or JSON (maybe in other formats).
Allows building distributed systems
It has the Discoverable feature. Resources can be easily identified
Very easy to use
Can use HTTP cache
What are REST constraints?
The main mechanism that indicates whether a service is a REST is its constraints.
REST has 6 (5 mandatories, 1 optional) constraints.
1) Uniform-Interface Constraint
This constraint is perhaps the most important constraint among REST constraints. If it is necessary to briefly list the main ideas on which it is based, we can say:
Different devices, equipment, and programs must use resources over the same URL
A URL can provide different representations. This is usually given as Content Negation in services. That is, by referring to the same URL, depending on the configuration, you can receive information in both XML and JSON format.
We can make both GET and POST requests to the same URL
The above brief overview is not complete. Because the Uniform-interface constraint itself consists of 4 sub-parts. If we don’t know them, it’s hard to fully understand what this limitation does:
1.1 Identification of Resources
Identification of resources should be done over URL. That is, it should be easy to know what type of resource is used when looking at the URL. Example: If the URL website.com/api/students is given, here students are our called and used as a resource. The name of the resource must be represented in the URL.
1.2 Manipulating Resources through representation
If the requesting client has permission to manipulate (edit, delete) the resource, there should be metadata about how to manipulate the resource together with the returned representation. Through these metadata links, the called resource can be changed or deleted.
1.3 Self-descriptive messages
Each sent request should be complete in itself, no additional commands should be needed to do any atomic work. Typically, metadata (additional credentials, HTTP method information, meta info) is sent via HTTP headers.
1.4 HATEOAS — (Hypermedia As The Engine of Application State)
During each request, it should be possible to receive documentation information, like a WSDL in WCF services. The point is that the client side should easily know where other resources are located (discoverable).
2) Client-Server constraint (Client Server constraint)
This constraint allows us to isolate the client and the server from each other.
There must be a client and a server for data exchange
They should be accompanied and expanded independently
They should not depend on each other
The client should not need to know anything about the architecture of the server
The server should not need to know anything about the client’s UI
3) Stateless constraint
Due to this limitation, the server and client should communicate without having information about each other.
The server should not store any session (data) about the client
The relationship between the client and the server is performed stateless, and all requests must be completely independent requests, not dependent on the results of other requests
4) Cachable constraint
The goal is to save the network and increase the exchange speed
If possible, the request from the server should be cached
During each response, it should be possible to manage the cache through the header
5) Layered system
The goal is to reduce complexity.
Server architecture is divided into the hierarchical layer (cover-abstraction level).
Each layer only knows about the middle layer
6) Code on demand constraint
This constraint is optional.
- In addition to simple data, the server can provide the client with the opportunity to execute some executable code examples. For example, to execute JS code. Just because this type of restriction is relatively dangerous, there is no obligation to implement it.
Want to dive deeper?
Every 5 days, I share my senior-level expertise on my DecodeBytes YouTube channel, breaking down complex topics like .NET, Microservices, Apache Kafka, Javascript, Software Design, Node.js, and more into easy-to-understand explanations. Join us and level up your skills!